

 CottonMD的构建和功能
CottonMD的构建和功能
CottonMD中基因组学和转录组学模块的使用
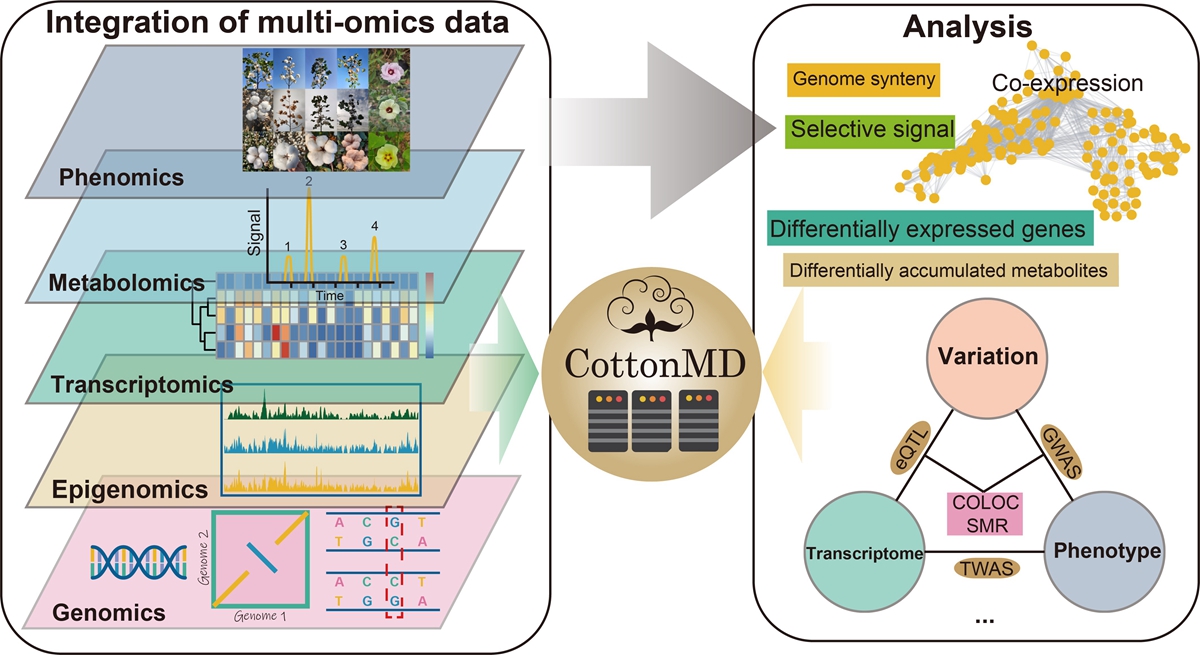
南湖新闻网讯(通讯员 杨植全)近日,我校信息学院与中国农科院棉花研究所、新疆农垦科学院等多单位在Nucleic Acids Research上联合发表题为CottonMD: a multi-omics database for cotton biological study的研究成果。该研究通过搜集和整合棉花基因组、转录组、变异组、表观遗传、表型组和代谢组等6个组学的数据,构建出目前最为系统和全面的棉花多组学数据库,为棉花遗传育种研究提供了重要的数据资源和分析平台。
棉花是世界上重要的天然纤维作物和战略物资。我国是世界上最重要的棉花生产国和原棉消费国,棉花事关国计民生。随着我国经济快速发展、人口持续增长和城镇化进程稳步推进,居民中高端纺织品消费量渐趋增长,棉纤维产需缺口持续扩大。当前我国棉花新品种的选育主要以传统遗传育种方法为主。该方法虽然取得了大量重要成果,但其挖掘候选重要育种价值基因的精度和效率都较低,极大地限制了新品种的选育进程。
近年来已逐渐发展成熟的多组学技术可以为研究者提供更广泛、更多维度的信息来加速育种进程,为解决传统遗传育种方法中存在的问题、加速实现精准育种提供了新的途径。为发挥多组学技术在育种中的价值,水稻、玉米、高粱等多个主要作物的多组学数据库平台相继建立,但仍缺少一个综合型的棉花多组学数据库平台。为解决这一问题,研究者通过整合25个棉花基因组、76个组织样本的转录组、5个物种的表观遗传学、4180个样本的群体遗传变异数据、20个表型和768个代谢物含量等公共多组学数据,构建了目前最为系统和全面的棉花多组学数据库-CottonMD。
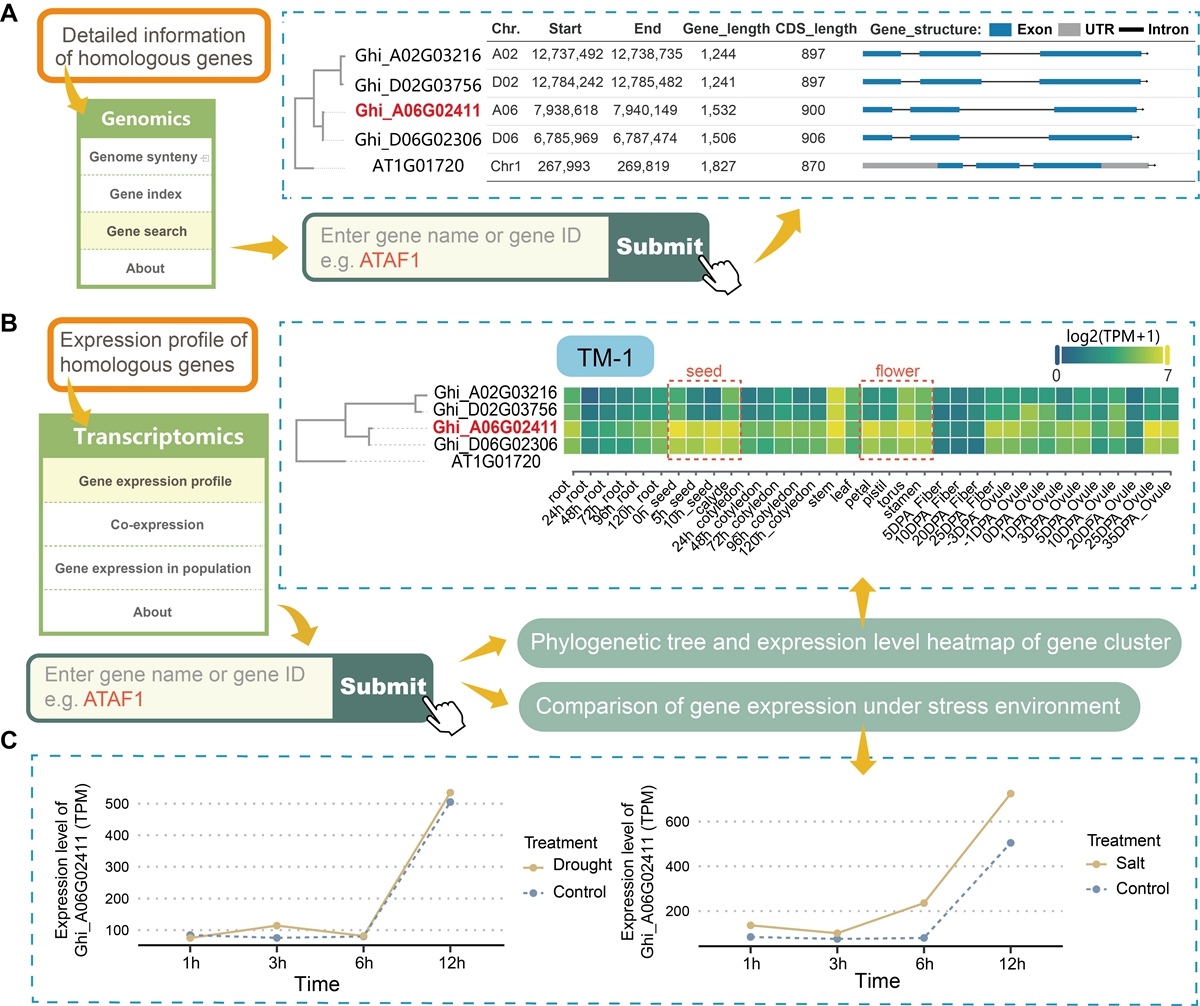
该数据库包含大量来自不同组学的信息。用户可以通过输入基因ID或物理位置信息来检索基因相关的多组学信息。以ATAF1基因为例,用户可以利用基因组模块获取4个同源基因的结构和功能信息,并通过转录组模块查询同源基因在不同组织、时期以及胁迫环境下的表达特征。这些功能为用户快速准确地理解基因的功能提供了可能。在该数据库中,研究者利用全基因组关联分析(GWAS)、表达数量性状位点定位(eQTL)、孟德尔随机化(SMR)和共定位分析等多组学关联分析方法对不同组学的棉花数据进行关联,并将分析结果和工具整合到数据库中以方便用户查询、分析和利用。
与现有的其他数据库相比,CottonMD是首个利用多种关联分析方法挖掘“变异-基因表达-表型”之间关联信息并提供相应数据可视化查询的数据库。此外,该数据库提供了最丰富的棉花多组学数据以及多种在线多组学分析和种质资源管理工具。在CottonMD中,所有模块均支持25个已发表棉花基因组的基因ID进行搜索、浏览和数据下载,以服务全球范围内的相关研究工作。
我校信息学院已毕业博士生杨植全(现广州大学博士后),硕士生王静和黄一鸣为论文并列第一作者,信息学院杨庆勇教授和中国农业科学院棉花研究所杨作仁研究员为论文共同通讯作者。新疆农垦科学院余渝研究员、石河子大学聂新辉教授对本项研究提供了指导。该项研究得到了国家重点研发计划(2021YFF1000100)、河南省自然科学基金(212300410093)、湖北省自然科学基金(2019CFA014)和海南省崖州湾种子实验室生物信息学开发平台(JBGS-B21HJ0001)等项目的资助。
审核人:杨庆勇
【英文摘要】
Cotton is an important economic crop, and many loci for important traits have been identified, but it remains challenging and time-consuming to identify candidate or causal genes/variants and clarify their roles in phenotype formation and regulation. Here, we first collected and integrated the multi-omics datasets including 25 genomes, transcriptomes in 76 tissue samples, epigenome data of five species and metabolome data of 768 metabolites from four tissues, and genetic variation, trait and transcriptome datasets from 4180 cotton accessions. Then, a cotton multi-omics database (CottonMD, http://yanglab.hzau.edu.cn/CottonMD/) was constructed. In CottonMD, multiple statistical methods were applied to identify the associations between variations and phenotypes, and many easy-to-use analysis tools were provided to help researchers quickly acquire the related omics information and perform multi-omics data analysis. Two case studies demonstrated the power of CottonMD for identifying and analyzing the candidate genes, as well as the great potential of integrating multi-omics data for cotton genetic breeding and functional genomics research.